
Fairness control for risky artificial intelligence decision making
Most of us living in the 2020’s get that machine learning algorithms are making automated decisions for us daily.
In fact, it is hard to even remember a world where applications such as Google Maps didn’t instruct us on the best route before setting out on a road trip. Many of these applications make decisions for us that are relatively harmless. Sure, I might prefer to be on the fastest route home after work, but if Google Maps makes a mistake and costs me an extra 5 minutes that’s OK.
But artificial intelligence (AI) systems are making decisions for and about us in ways that largely remain invisible. And that’s not a design flaw, it’s how things are intended to be — barely perceptible to the ‘user’. Or the used.
However instances of unjust discrimination in the operation of many routine AI have come to light in recent years. This is troubling when compounded with the fact that many AI algorithms don’t offer much insight into why they give the answers that they do. Think about ChatGPT: we know that its answers tend to be accurate but we don’t have any idea how certain, or why, it is giving us those responses. Together with my colleagues, I developed an algorithm that is guaranteed to make the outputs of any AI decision making model fair, without having to fully know its inner workings. But first, let’s first appreciate the extent of the problem.
It’s an AI life
Another common example of the use of AI for automated decision making that may impact our quality of life is border control at Sydney’s Kingsford Smith Airport. Travelers are well acquainted with the facial recognition system awaiting them upon return to Australia. This system has certainly created a much more streamlined process for airport security to check for potential criminals or illegal activity at the border. But this efficiency comes at a cost: handing over to an AI algorithm the decision of who is, or is not, a criminal. The consequences of making an incorrect decision here and accidentally identifying an innocent individual as a criminal can have devastating consequences on their life (or at least certainly the next few hours!). So we need to take extra care when making automated decisions in settings where the consequences of making a mistake can have a high impact on someone’s quality of life.
Taking extra care with automated decisions might sound surprising. Aren’t AI decisions more accurate than human ones? While we have a lot of evidence that AI systems can be very accurate, it is hard for humans (even top researchers) to say why AI systems give us the answers they do. Consider again our example of facial recognition at the border. Perhaps the AI system has identified someone as a criminal because they truly are a criminal. Or perhaps they have been identified because the algorithm has made an incorrect connection that people with orange hair have tended to be risky individuals in the past. It would be great to understand when AI is making a decision based on the former set of principles rather than the latter. But currently, even top statisticians and computer scientists still struggle with distinguishing between these scenarios.
Algorithms can be accurate but also unfair
Our lack of knowledge into why these “black box” AI models work can cause a lot of problems in practice. When we do not know why algorithms make the decisions they do, this can lead to automatic decisions that are untrustworthy and unfair to minority groups. AI models are really good at giving us accurate decisions with respect to historical data sets with previous decisions. However, when we do not know the reasoning why a model is making its decisions, it is possible to be accurate while also being unfair.
Consider a simplified example where an AI model looks at one thousand criminal defendants appearing in a court trial and decides that 100 of them are criminals. If this AI is using the latest technology, perhaps we can guarantee that in the long run, it never makes more than 5% of mistakes when identifying true criminals. That means of the 100 defendants, we would expect that approximately no more than 5 of the 100 defendants are incorrectly classified as criminals. However, this should not be the end of the story.
We should demand to know more about how this accuracy was obtained. For example, what if the AI algorithm decided that a specific minority group was more likely to be a criminal solely based on someone’s membership of a protected group (such as female or male)? If this was the case, then it would be very likely that most (if not all) of the 5 mistakes all belonged to minority groups. That would indeed be unfair because it would mean that our algorithm was more or less accurate depending on your minority group. I don’t know about you, but I wouldn’t want an AI algorithm used against me if I knew that it was very inaccurate based on characteristics about myself that I couldn’t change.
These problems aren’t just contrived scenarios. They are real issues that practitioners face every day when trying to make automated decisions. Consider a bank that wants to use an AI to issue loans to applicants it is confident will repay the loan. Not only is the bank incentivised to offer as many loans as possible to credit worthy applicants, but it also wants to make sure it does so fairly. Not only is this a moral imperative, banks need to ensure they are fairly serving their community, but often it is also a legal one.
This phenomena can be observed in a variety of situations. Areas such as facial recognition, criminal recidivism prediction, and loan applications (among many others) have observed these issues. When AI algorithms are used in highly sensitive areas, we need to ensure that everyone (regardless of their membership of a minority group) has an equal opportunity within the systems that we all need to navigate in life.
Building fairness on top of an algorithm
My research focuses on better communicating unfairness in automated decisions to practitioners, so they don’t have to completely rely on the output of a black box AI without much knowledge as to why it is giving a partiular answer. Crucially, my work rigorously controls fairness when an algorithm makes a high stakes decision and ensures that decisions are only made when an AI algorithm is highly confident about the accuracy and fairness of this decision. If the AI is not confident it is making a fair decision, these observations are then turned over to the human to determine a better course of action for those individuals for whom the automated decision is not suitable.
If this was applied to our facial recognition example, then instead of arresting a possibly innocent person the algorithm will decide not to make a decision about them. This would then require a further review by airport staff, avoiding costly incorrect investigations and a large amount of societal burden on the individual.
The procedure that my co-authors and I developed is called Fairness Adjusted Selective Inference, or FASI for short. It can work with any AI model (without knowledge of its complicated inner processes) and select individuals for high-risk decisions with rigorous fairness control over the definitive decisions made across minority groups. Controlling for the rate of erroneous decisions across minority groups for the observations that an algorithm makes a decision on has a lot of benefits. However, it is certainly not the right thing to do in every situation. For example, if you believe that within a minority group there are fairness concerns you may want to consider alternative approaches.
The FASI effect
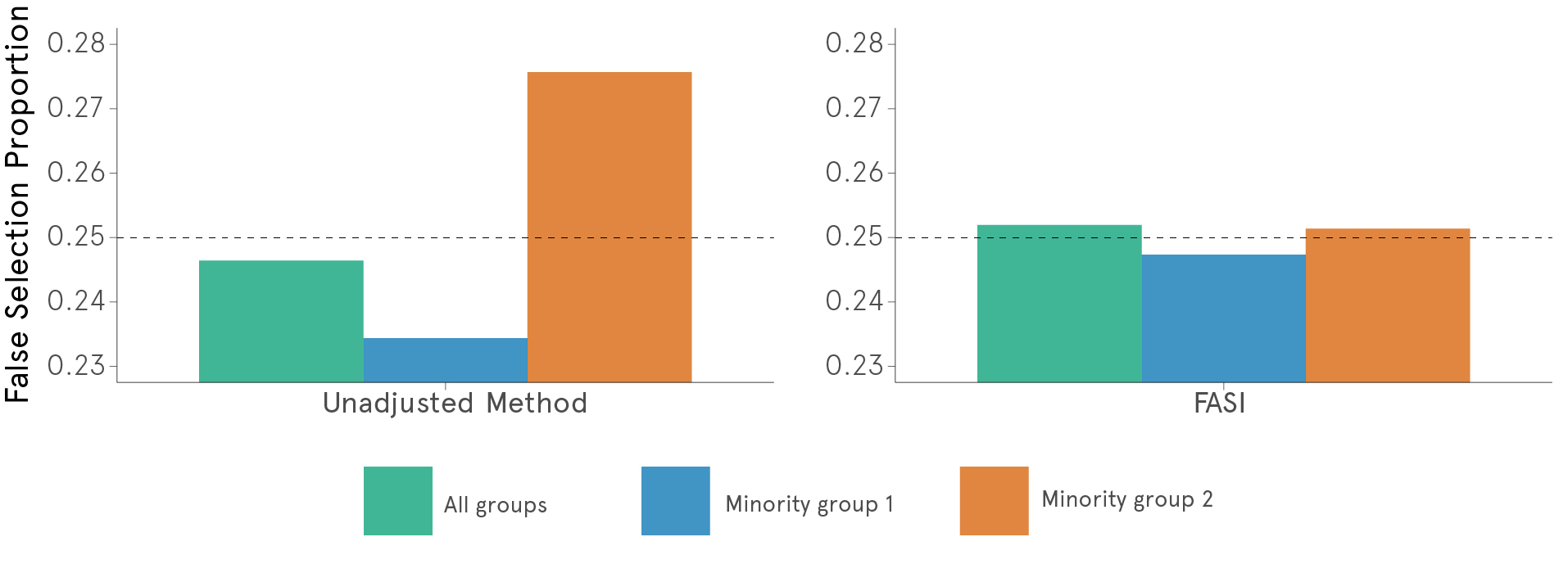
The FASI framework can be used in tandem with any black box machine learning algorithm without any requirements on the accuracy of its responses. It is guaranteed to have fair control over all minority groups for the decisions that the AI model is currently making. It will not only benefit the people about whom the decisions are being made, but it also will help practitioners using the model because it will help them review harder to classify cases without first making a costly incorrect decision on them.
The FASI algorithm has been jointly developed by Bradley Rava, Wenguang Sun, Gareth M. James, and Xin Tong and presented in their paper, A Burden Shared is a Burden Halved: a Fairness Adjusted Approach to Classification
Bradley is a Lecturer in the Discipline of Business Analytics at the University of Sydney Business School. His research focuses on Empirical Bayes techniques, Fairness in Machine Learning, Statistical Machine Learning, and High Dimensional Statistics.







